 由 Brian Dean · 更新于 2019年9月
由 Brian Dean · 更新于 2019年9月

Robots.txt是一个文件,它告诉搜索引擎蜘蛛不要抓取网站的某些页面或部分。大多数主要的搜索引擎(包括Google、Bing和Yahoo)都会识别并尊重Robots.txt请求。
大多数网站不需要robots.txt文件。
这是因为Google通常可以找到并索引你网站上所有的重要页面。
而且他们不会自动索引那些不重要的页面或其他页面的重复版本。
有3个使用robots.txt文件的理由:
一句话:robots.txt会告诉搜索引擎蜘蛛不要抓取你网站上的特定页面。
你可以在Google站长工具中检查你有多少页面被索引。
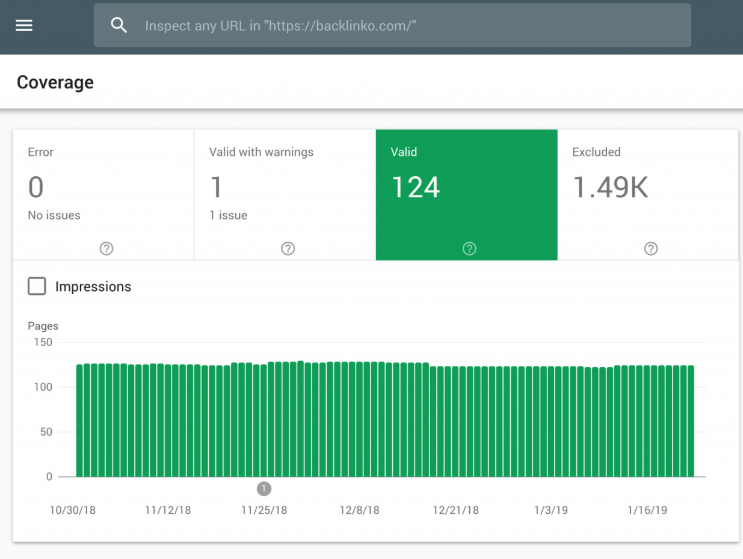
如果这个数字与你希望被索引的页面数量相匹配,那么你就不需要再费心建立Robots.txt文件了。
但如果这个数字比你预期的要高(而且你注意到了不应该被索引的URL),那么是时候为你的网站创建一个robots.txt文件了。
你的第一步是实际创建你的robots.txt文件。
作为一个文本文件,你实际上可以使用Windows记事本创建一个。
无论你最终如何制作robots.txt文件,格式都是一样的。
User-agent: X
Disallow: Y
User-agent是你具体的搜索引擎爬虫。
而 “disallow “后面的所有内容都是你要屏蔽的页面或目录。
下面是一个例子:
User-agent: googlebot
Disallow: /images
这个规则会告诉Googlebot不要索引你网站的图片。
你也可以使用星号(*)来告诉所有搜索引擎爬虫停止在你的网站上爬取。
例如:
User-agent: *
Disallow: /images
“*”告诉任何和所有蜘蛛不要抓取你的图片。
这只是许多使用robots.txt文件的方法之一。这个来自Robots.txt是一个文件有更多的信息,你可以使用不同的规则来阻止或允许搜索引擎爬虫抓取你的网站的不同页面。

一旦你有了robots.txt文件,是时候让它活起来了。
技术上来说,你可以把robots.txt文件放在网站的任何主目录下。
但为了增加robots.txt文件被发现的几率,我建议把它放在以下位置:
https://example.com/robots.txt
注意,你的robots.txt文件是区分大小写的。因此,请确保在文件名中使用小写的 “r”)
你的robots.txt文件的设置是否正确是非常重要的。一个错误,你的整个网站可能会被取消索引。
幸运的是,你不需要希望你的代码设置正确。Google有一个有趣的Robots测试工具,你可以使用。
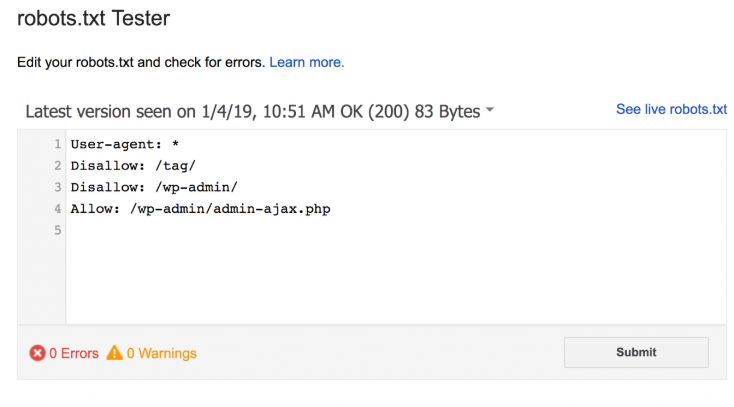
它会显示你的robots.txt文件….以及它发现的任何错误和警告:

如你所见,我们阻止蜘蛛爬行我们的WP管理页面。
我们还使用robots.txt来阻止抓取WordPress自动生成的标签页面(限制重复内容)。
当你可以用 “noindex “meta标签在页面级阻止页面时,为什么要使用robots.txt?
就像我之前提到的,noindex标签在多媒体资源上实现起来很麻烦,比如视频和PDF。
另外,如果你有成千上万的页面想被屏蔽,有时用robots.txt来屏蔽整个网站的所有页面,比手动添加noindex标签更容易。
也有一些边缘情况,你不想浪费任何抓取预算,让谷歌在有noindex标签的页面上着陆,这也是边缘情况。
话虽如此。
在这三种边缘情况之外,我建议使用meta指令而不是robots.txt。它们更容易实现。而且致命作物发生的几率也比较小(比如屏蔽了你的整个网站)。
 杭州**电子商务有限公司 时尚服饰
杭州**电子商务有限公司 时尚服饰
“刚接触Google SEO,是个小白,全得益于运营的及时回复和细心教导,才对外贸商桥SEO系统开始熟悉, 从基础信息到优化技巧,服务都十分周到,所以很感谢优化团队的人性化和全面化的服务。”
 陈先生 家居用品
陈先生 家居用品
“系统功能完善,现有功能性价比比较高,Google SEO对站点长期帮助非常大,而且需要时间沉淀,现在网站流量和关键词排名比原来好多了,确实很有效果,非常满意。”
 许昌***有限公司 美妆产品
许昌***有限公司 美妆产品
“2019年选择用使用外贸商桥SEO优化的系统,初期给我们的感觉是非常容易上手,网站监测很方便,每天都会生成报表。 而且数据跟踪全面,来源渠道和客户区域、停留时间都有,非常专业,优化效果非常好。 感谢外贸商桥团队给我们提供了值得信赖的电商系统。”
如果您是营销版用户,您可以使用系统所有功能。如果是服务版、旗舰版用户, 我们为您做网站优化,包含关键词分析、网站检测、全站优化等,并保证首页关键词排名数量。
作为一个正规的SEO服务商,实施SEO项目是需要时间的,一般1~3个月初见成效,比如:流量增加、关键字排名上升、搜索引擎表现改善等。 我们绝大部分客户都是提前达标,并获得满意效果。
我们基于Google SEO优化标准来优化站点,使用的是白帽SEO,不会导致网站降权、被K。
在SEO服务过程排名可能会出现波动,特别是对于一些新站的排名波动有时候幅度会比较大,这是个正常的过程,一般在一段时间内会恢复,恢复后不再波动。
SEO优化是个持续的过程,不是说排名上首页后不做了就可以一直存在的,排名是相对存在的,不进则退,我们只能说合作期内保证排名。不合作了,后面排名是没办法保证的。停止合作后关键词排名一般情况下不会马上就会掉的,排名上升需要一个过程,同样下降也需要一个过程。 这个周期是多久主要是有网站的本身权重和关键词当前的竞争度决定的。






